


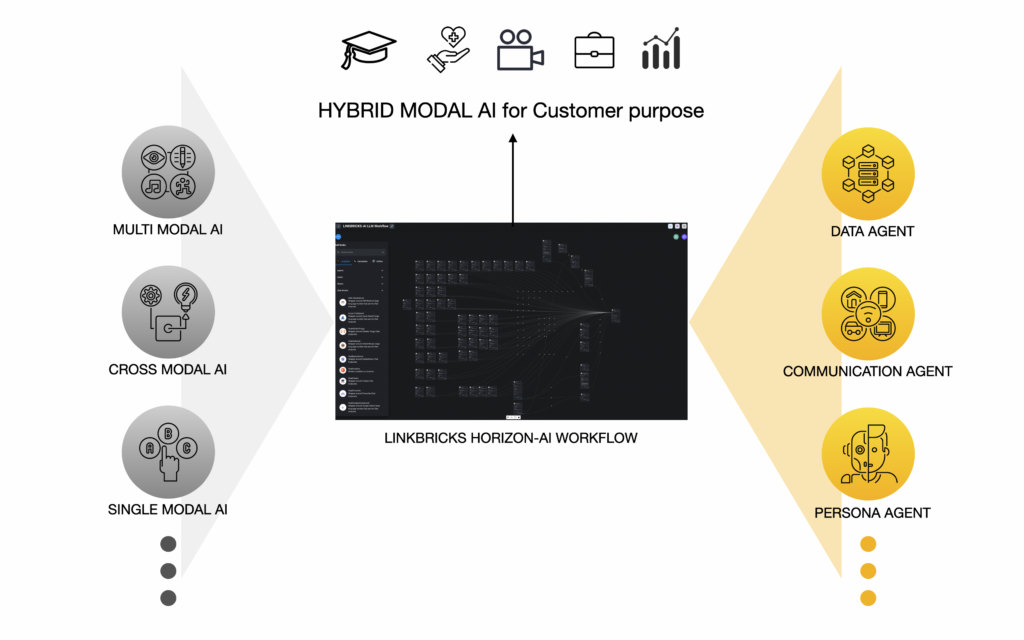
Text
text-based Cross Modal LLMs with varying parameter sizes

Voice
Synchronous, asynchronous, and real-time voice LLM

Image
Low-cost LLM for text-to-image, image-to-text, and image-to-image

Music
Fast and cost-effective LLM for music generation, music-to-music, and text-to-music

Video
Low-cost LLM for video generation, text-to-video, and video-to-text

Physical
Genesis and Omniverse Physics platform designed for general-purpose Robotics/Embodied AI/Physical AI with LLMs















