Beyond Traditional RAG: From “Retrieval AI” to “Learning, Understanding, and Connecting AI”
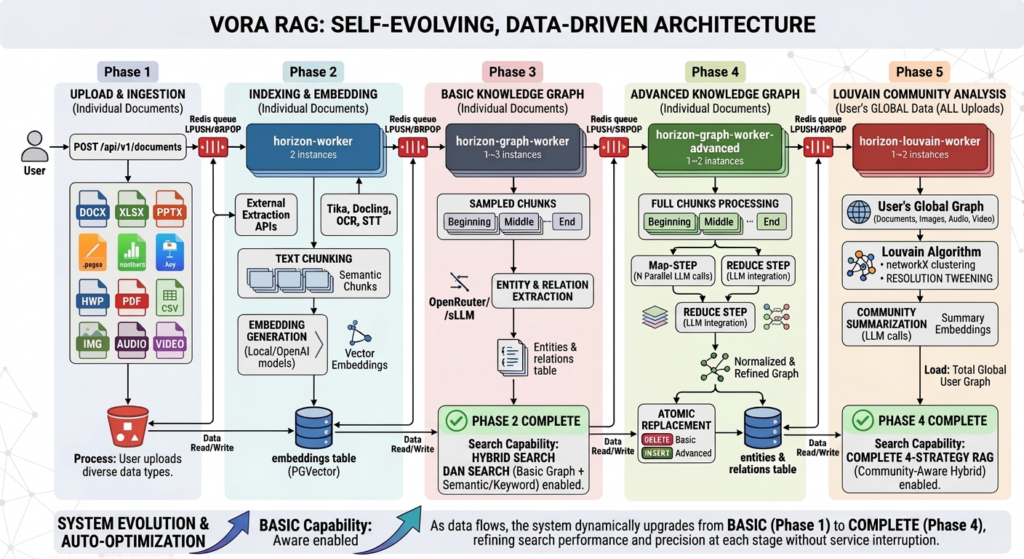
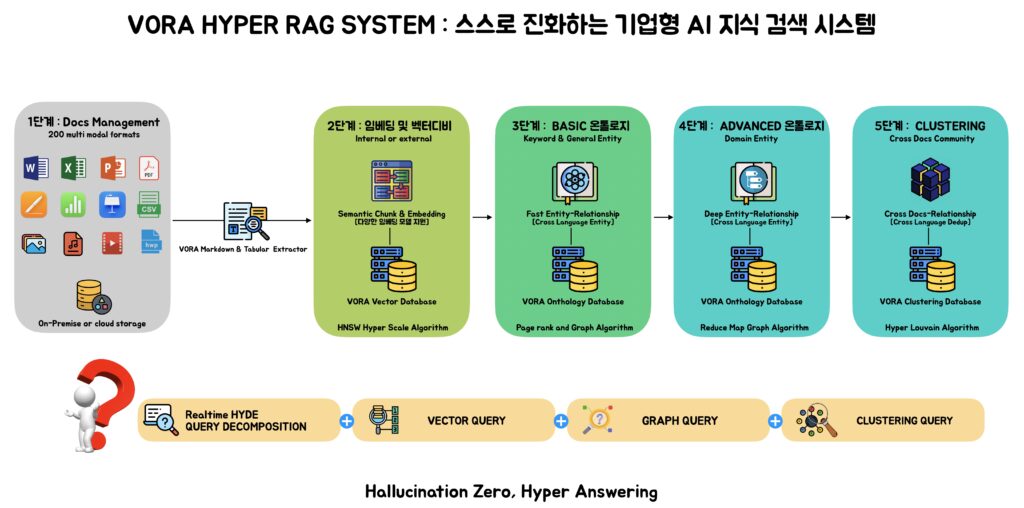
VORA HYPER RAG is designed to progressively structure and interconnect an enterprise’s entire document and data assets, enabling increasingly accurate and context-aware answers over time.
Unlike conventional systems that rely on a single retrieval method, VORA HYPER RAG combines:
This hybrid approach delivers significantly more stable and precise results.
In addition, the system continuously learns and evolves from user-specific documents, allowing the RAG system itself to improve over time.
Multimodal Enterprise AI: Beyond Documents
Enterprise data is no longer limited to PDFs and text documents. Real-world workflows involve a wide variety of formats, including:
MS Office documents
PDFs
HWP (Hangul Word Processor)
Apple iWorks (Pages, Numbers, Keynote)
Images, audio, and video
VORA HYPER RAG is built as a fully multimodal enterprise AI system, capable of processing and understanding all of these formats simultaneously.
Advanced Tabular Data Handling: In-Memory Database for CSV & Excel
Traditional RAG systems often struggle with tabular data such as CSV and Excel files, due to limited understanding of row-column relationships and structured queries.
VORA HYPER RAG automatically generates an in-memory database when processing tabular data. This enables:
As a result, tabular data can be queried as if it were a fully structured database—dramatically improving search and QA performance.
All of this is handled through high-speed parallel processing, ensuring no degradation in response time.
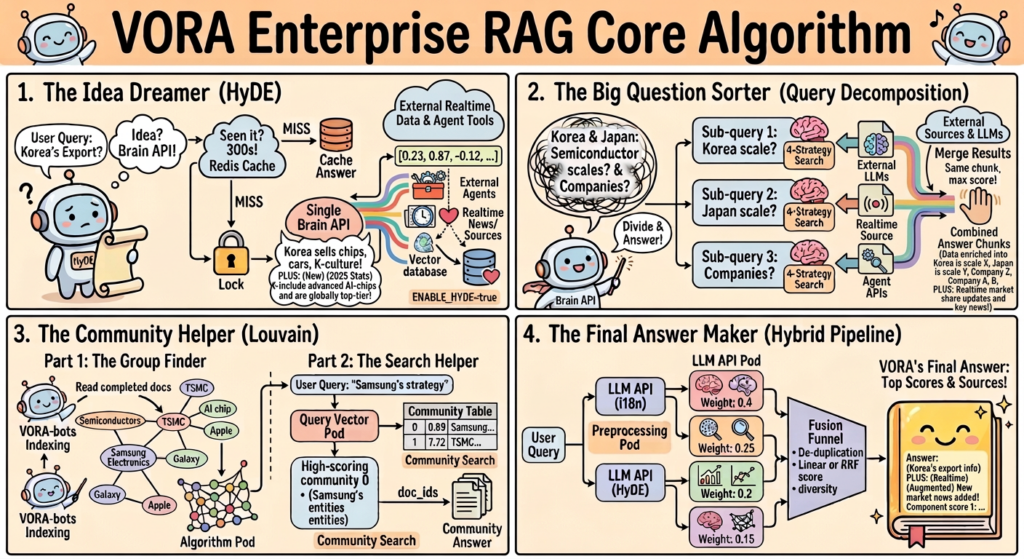
Accurate Responses to Short & Abstract Queries: HYDE Engine Integration
To address the limitations of traditional RAG systems in handling short, abstract, and context-dependent queries, VORA HYPER RAG integrates the HYDE (Hypothetical Document Embedding) engine.
This approach:
Transforms user queries into enriched hypothetical documents
Enhances semantic understanding of intent and context
Improves retrieval accuracy even for ambiguous questions
Intelligent Agent Workflows: Combining Internal and Real-Time Data
The HYDE engine is tightly integrated with Linkbricks Horizon AI’s intelligent agent workflow system, enabling more than just document retrieval.
It allows:
Users can perform advanced analysis that combines internal documents with live data through a single API.
For example:
A query like “Analyze today’s Samsung Electronics disclosure based on yesterday’s filing”
can seamlessly combine historical documents with real-time disclosures to produce comparative insights.
Knowledge Graph–Driven Multilingual Clustering
VORA HYPER RAG goes beyond document-level analysis by building knowledge graphs based on extracted entities and relationships across the entire dataset.
This enables:
Multilingual clustering across Korean, English, Japanese, Chinese, and more
Cross-language concept linking
Deeper and broader contextual understanding as data accumulates
A proprietary high-speed algorithm—capable of operating without GPUs—has been developed and filed for patent.
Unified System & Single API Architecture
Traditional enterprise AI systems often rely on fragmented infrastructures:
Each typically requires separate storage and APIs.
VORA HYPER RAG unifies all of these into a single integrated system, including:
This allows developers and users to access the full capabilities of enterprise AI search and analytics through just one API, without needing to manage underlying complexity.
Flexible Deployment: Cloud & On-Premise
To meet enterprise requirements, VORA HYPER RAG supports both:
Cloud deployment
On-premise deployment
Organizations can choose the model that best aligns with their: